Architectural Foundations#
The Spiking Decision Transformer (SNN-DT) is a novel integration of biologically-inspired computation with sequence-based offline reinforcement learning. By recasting offline RL as an autoregressive next-token prediction problem, the Decision Transformer (DT) established a powerful paradigm. However, the energy and memory demands of traditional Transformers severely limit edge deployment.
SNN-DT addresses this fundamental limitation by introducing three foundational neuromorphic innovations into the return-conditioned Transformer pipeline.
Figure 1: Overall architecture of the Spiking Decision Transformer. The offline trajectory embeddings (return, state, action) pass into the Phase-Shifted Positional Encoder. Spiking Self-Attention blocks interact dynamically with a Dendritic Routing MLP, culminating in a sparse action projection governed by Three-Factor Plasticity.
1. Phase-Shifted Positional Spiking#
In traditional Transformers, temporal order is preserved via floating-point scalar positional embeddings. SNN-DT entirely discards analog coordinate embeddings in favor of phase-shifted, spike-based encoders.
For each of the \(H\) attention heads, the model learns a distinct frequency \(\omega_k\) and a phase offset \(\phi_k\). At token position timestep \(t\), head \(k\) emits a binary spike train derived from a sine-threshold generator:
This mechanism endows each attention head with a distinct rhythmic code, providing a set of orthogonal temporal basis functions natively in the event domain.
2. Spiking Self-Attention & Dendritic Routing#
SNN-DT maps continuous embeddings into sparse spike rates via Leaky Integrate-and-Fire (LIF) dynamics. To adaptively combine parallel attention head outputs without uniform averaging, we leverage a lightweight Dendritic-Style Routing MLP.
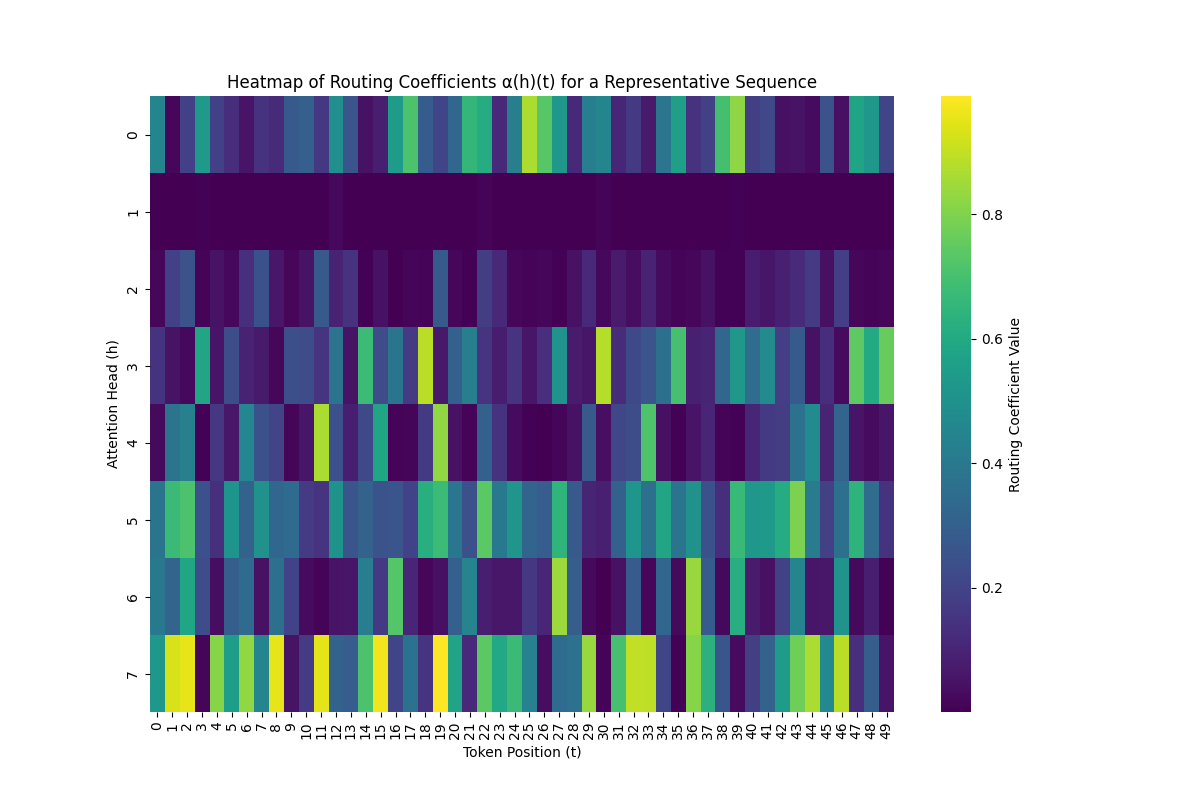
Figure 2: Heatmap illustrating dynamic, context-dependent routing gating coefficients \(\alpha^{(h)}_i(t)\) per head across a sequence. Darker cells indicate effectively pruned or suppressed head outputs, securing computational sparsity.
Inspired by biological dendritic arborization, this routing mechanism computes context-dependent gating coefficients \(\alpha^{(h)}_i(t) \in (0,1)\) across all head outputs \(y^{(h)}_i(t)\) at a given timestep.
The globally routed representation for token \(i\) becomes a sparse, gated sum:
This token-specific recombination extracts complementary computational properties (e.g., short vs. long-range dependencies) with negligible parameter overhead.
3. Local Three-Factor Plasticity#
Replacing dense global gradient signals during online fine-tuning, the SNN-DT employs a biologically-grounded three-factor plasticity rule directly inside the action-head. Credit assignment is securely localized into an eligibility trace bounded by a generic temporal decay rule.
For pre-synaptic vector \(x_t\) and post-synaptic activity \(y_t\), the eligibility trace \(E_{ij}(t)\) maintains Hebbian co-activations:
Given a scalar modulatory signal derived from the offline return-to-go \(\delta_t = f(G_t)\), the localized weight update effectively becomes:
This restricts catastrophic forgetting and reduces computational footprint by avoiding full backpropagation through time across earlier Attention/LIF layers blocks.